RUST--01 | 内存:值,放在栈上还是堆上??
牢骚话
学习 Java、Python 或者 Scala 的时候,通常都会从最基本的语法讲起,为何谈起 Rust 却偏偏要从这些较为抽象的基础知识谈起呢?其实不然,从我自己的经历来说,吃过基础知识没学透,后期回来补课的痛苦。。。
比如,以最基础的内存为例,很多人其实并没有搞懂什么时候数据应该放在栈上,什么时候应该在堆上,直到工作中实际出现问题了,才意识到数据的存放方式居然会严重影响并发安全,无奈回头重新补基础,时间精力的耗费都很大。
作为一名开发者,会遇见很多工具、框架和语言,但这类东西无论怎么变,底层的逻辑都是通用的,正所谓“万变不离其宗”。
在学习一门新的语言中,最基本的概念就是代码中的变量和值,而存放它们的地方是内存,那么你真的有了解过内存吗??
内存
从写代码开始,我们就无时无刻不和内存在打交道。比如下面这行代码:
| |
首先,“hello world”作为一个字符串常量(string literal),在编译时被存入可执行文件的 .RODATA 段(GCC)或者 .RDATA 段(VC++),然后在程序加载时,获得一个固定的内存地址。当执行“hello world”.to_string() 时,在堆上,一块新的内存被分配出来,并把“hello world”逐个字节拷贝过去。
当我们把堆上的数据赋值给 s 时,s 作为分配在栈上的一个变量,它需要知道堆上内存的地址,另外由于堆上的数据大小不确定且可以增长,我们还需要知道它的长度以及它现在有多大。
最终,为了表述这个字符串,我们使用了三个 word:
- 第一个表示指针;
- 第二个表示字符串的当前长度(11);
- 第三个表示这片内存的总容量(11);
在 64 位系统下,三个 word 是 24 个字节。也可以看下图,更直观一些:
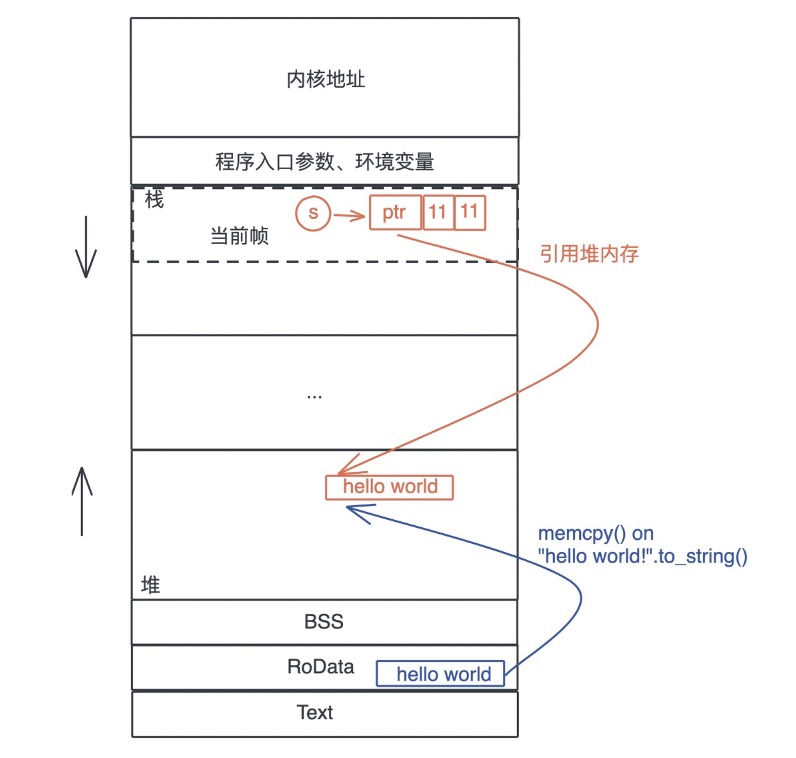
刚才例子中的字符串的内容在堆上,而指向字符串的指针等信息在栈上,那么有个问题就是:数据什么时候可以放在栈上,什么时候需要放在堆上呢?
这个问题也是比较考验程序员的基本功是否扎实的,很多使用自动内存管理语言比如 Java/Python 的开发者,可能有一些模糊的印象或者规则:
- 基本类型(primitive type)存储在栈上,对象存储在堆上;
- 少量数据存储在栈上,大量的数据存储在堆上。
这么回答,虽然对,但并没有抓到实质。如果在工作中只背规则套公式,一遇到特殊情况就容易懵,但是如果明白公式背后的推导逻辑,即使忘了,也很快能通过简单思考找到答案,所以接下来我们深挖堆和栈的设计原理,看看它们到底是如何工作的。(btw 如果连公式都不会背的话 emmmm。。。。。dddd😁)
栈
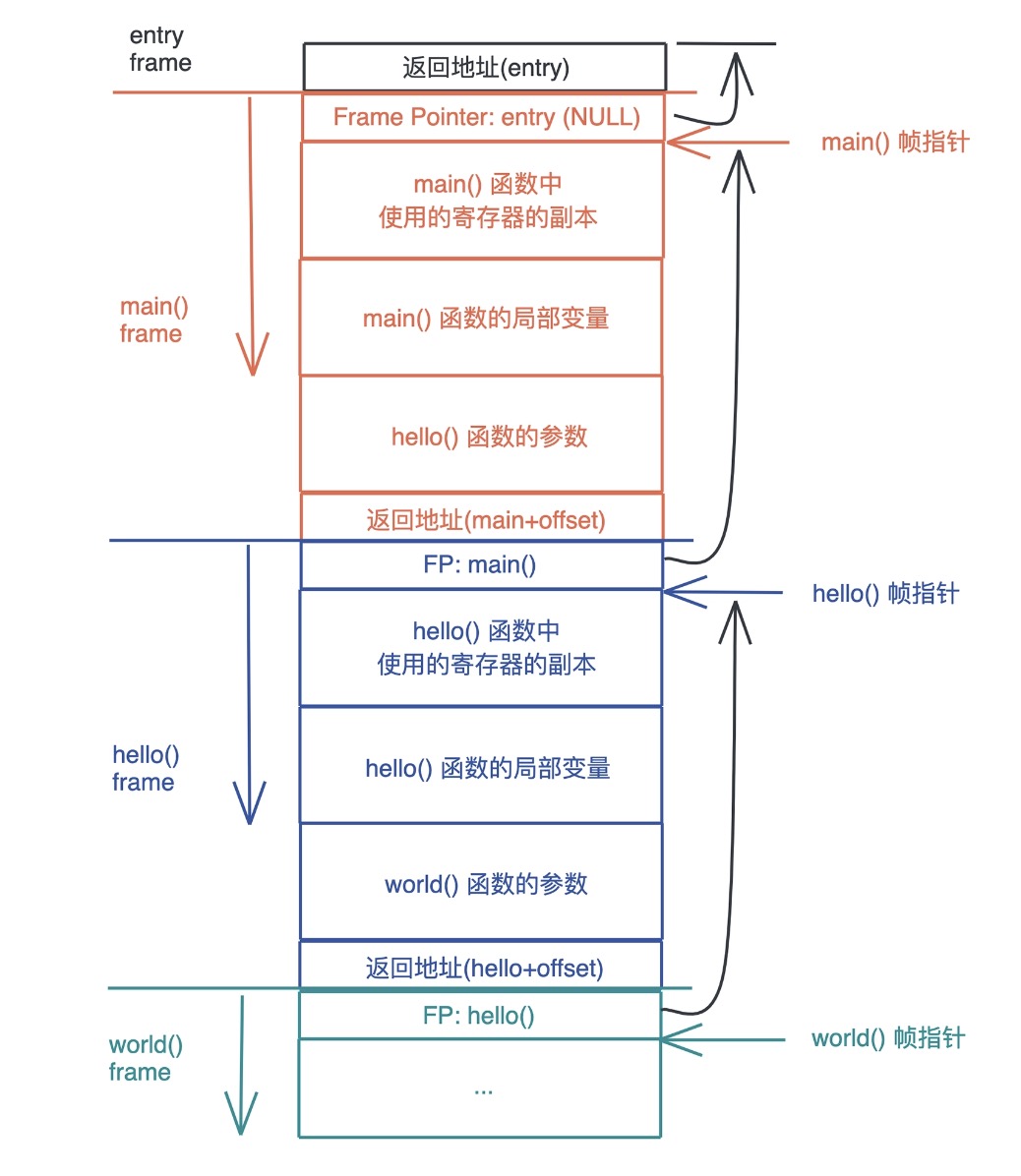
栈是程序运行的基础。每当一个函数被调用时,一块连续的内存就会在栈顶被分配出来,这块内存被称为帧(frame)。
栈是自顶向下增长的,一个程序的调用栈最底部,除去入口帧(entry frame),就是 main() 函数对应的帧,而随着 main() 函数一层层调用,栈会一层层扩展;调用结束,栈又会一层层回溯,把内存释放回去。
在调用的过程中,一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当这个函数调用结束,通过副本,可以恢复出原本的寄存器的上下文,就像什么都没有经历一样。此外,函数所需要使用到的局部变量,也都会在帧分配的时候被预留出来。
整个过程可以再看看这张图辅助理解:
那一个函数运行时,怎么确定究竟需要多大的帧呢?这要归功于编译器。在编译并优化代码的时候,一个函数就是一个最小的编译单元。
在这个函数里,编译器得知道要用到哪些寄存器、栈上要放哪些局部变量,而这些都要在编译时确定。所以编译器就需要明确每个局部变量的大小,以便于预留空间。
于是乎我们可以这么理解:在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。比如一个函数,参数是字符串:
| |
字符串的数据结构,在编译时大小不确定,运行时执行到具体的代码才知道大小。比如上面的代码,“Lindsey”和“Rosie”的长度不一样,say_name() 函数只有在运行的时候,才知道参数的具体的长度。所以,我们无法把字符串本身放在栈上,只能先将其放在堆上,然后在栈上分配对应的指针,引用堆上的内存。
放在栈上的问题
从刚才的图中也可以直观看到,栈上的内存分配是非常高效的。只需要改动栈指针(stack pointer),就可以预留相应的空间;把栈指针改动回来,预留的空间又会被释放掉。预留和释放只是动动寄存器,不涉及额外计算、不涉及系统调用,因而效率很高。
所以理论上说,只要可能,我们应该把变量分配到栈上,这样可以达到更好的运行速度。那为什么在实际工作中,我们又要避免把大量的数据分配在栈上呢?这主要是考虑到调用栈的大小,避免栈溢出(stack overflow)。
一旦当前程序的调用栈超出了系统允许的最大栈空间,无法创建新的帧,来运行下一个要执行的函数,就会发生栈溢出,这时程序会被系统终止,产生崩溃信息。过大的栈内存分配是导致栈溢出的原因之一,更广为人知的原因是递归函数没有妥善终止。一个递归函数会不断调用自己,每次调用都会形成一个新的帧,如果递归函数无法终止,最终就会导致栈溢出。
堆
栈虽然使用起来很高效,但它的局限也显而易见。当需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。
堆上分配内存时,一般都会预留一些空间,这是最佳实践。比如你创建一个列表,并往里添加两个值:
| |
这个列表实际预留的大小是 4,并不等于其长度 2。这是因为堆上内存分配会使用 libc 提供的 malloc() 函数,其内部会请求操作系统的系统调用,来分配内存。系统调用的代价是昂贵的,所以要避免频繁地 malloc()。
对上面的代码来说,如果说需要多少就分配多少,那列表每次新增值,都要新分配一大块的内存,先拷贝已有数据,再把新的值添加进去,最后释放旧的内存,这样效率很低。所以在堆内存分配时,预留的空间大小 4 会大于需要的实际大小 2。
除了动态大小的内存需要被分配到堆上外,动态生命周期的内存也需要分配到堆上。
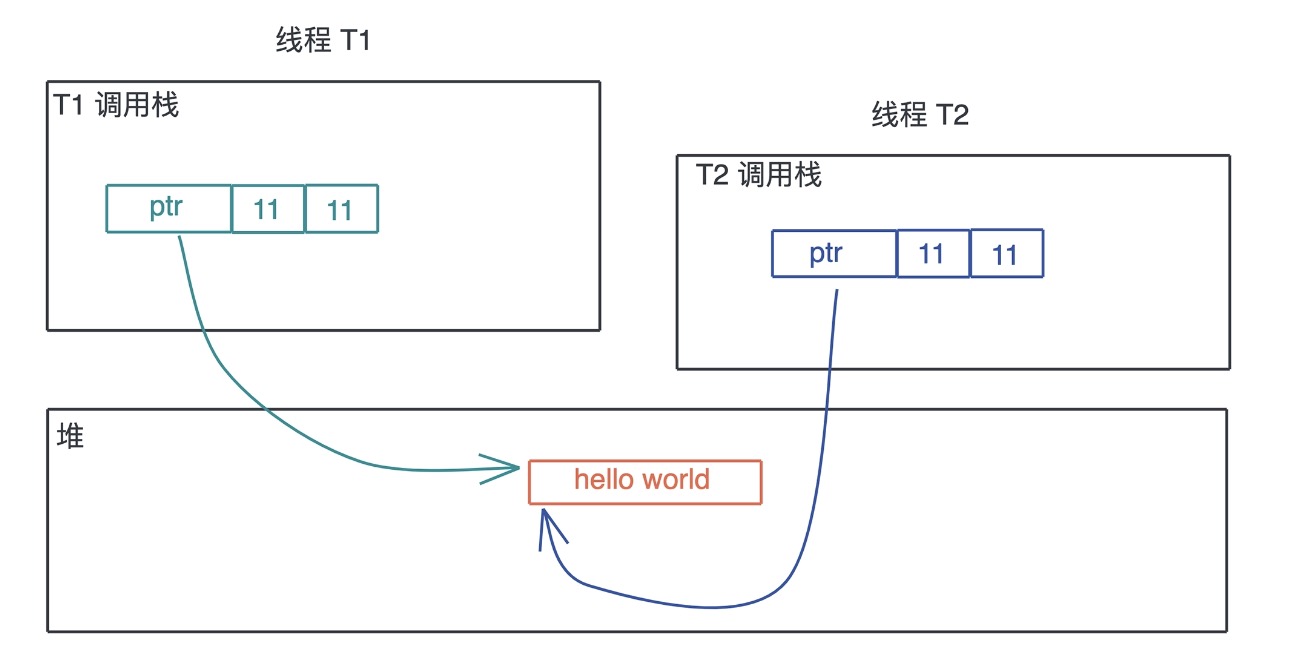
上文中我们讲到,栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。而堆上分配出来的每一块内存需要显式地释放,这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。
放在堆上的问题
然而,堆内存的这种灵活性也给内存管理带来很多挑战。
如果手工管理堆内存的话,堆上内存分配后忘记释放,就会造成内存泄漏。一旦有内存泄漏,程序运行得越久,就越吃内存,最终会因为占满内存而被操作系统终止运行。
如果堆上内存被多个线程的调用栈引用,该内存的改动要特别小心,需要加锁以独占访问,来避免潜在的问题。比如说,一个线程在遍历列表,而另一个线程在释放列表中的某一项,就可能访问野指针,导致堆越界(heap out of bounds)。而堆越界是第一大内存安全问题。
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能发生使用已释放内存(use after free)的情况,程序轻则崩溃,重则隐含安全隐患。根据微软安全反应中心(MSRC)的研究,这是第二大内存安全问题。
小结
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC,都有性能损耗和其它问题。
一句话对比总结就是:栈上存放的数据是静态的,固定大小,固定生命周期;堆上存放的数据是动态的,不固定大小,不固定生命周期。